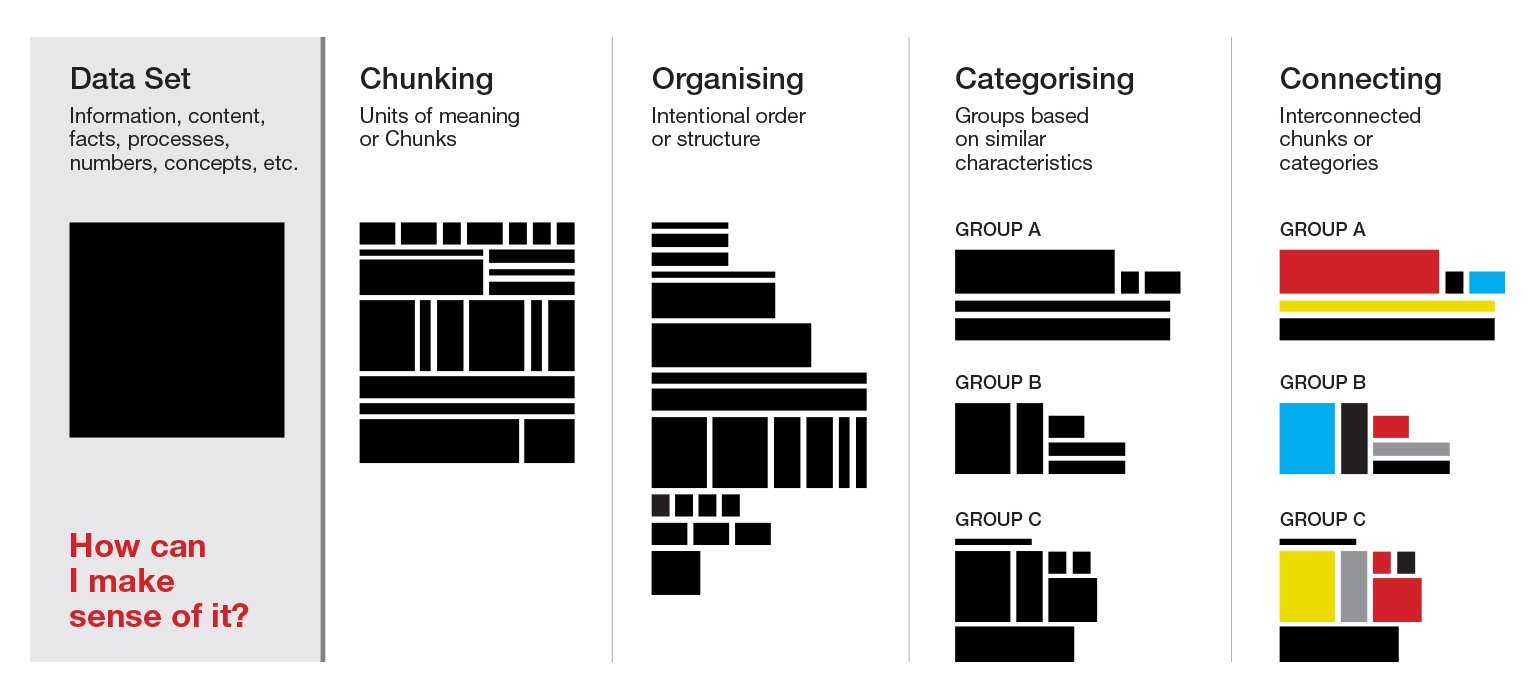
Sometimes, making sense of data* can be challenging. Data is often perceived this way when a data set is too big or too complex. This indicates that size (small/big) and nature (simple/complex) are frequent issues that can influence the sensemaking process.
In these cases, why is data hard to make sense of?
Size. Not surprisingly, having loads of data makes the sensemaking process harder. On the one hand, it will certainly take much more time to make sense of a large data set than of a small one. But what really has a stronger impact in how we gain an understanding is whether data is organised and the way it is presented to us. The more disorganised a data set is the harder it is to make sense of. This is because the brain perceives and understands information as organised information fragments (Moles, 1966; Dorst and Lawson, 2009). When data is disorganised the brain struggles to perform the necessary cognitive actions to make sense of something, and needs to use larger amounts of cognitive energy to extract meaning.
Nature. Our degree of familiarity with the topic of a data set determines whether we find it simpler or more complex. When we are unfamiliar with the core topic of a data set or with the majority of its many interacting parts (e.g. sub-topics, stories, key characters, locations, etc.), we cannot rely on our previous knowledge to find answers, connections or gain an understanding. Before starting to make sense of it, first we need to learn and get familiar with the topic. This learning process will help construct and store the necessary frames in the brain that then will be used for sensemaking. These activities consume high levels of cognitive energy too.
How do we make sense of data?
Most cognitive activities involved in the sensemaking process aimed to help gain a better understanding of something (e.g. a situation, a story, a conversation, a task, a problem, etc.), while also helping the brain economise energy. Below some of these key activities:
- Break down the topic into chunks. The part of the brain that is used to digest new information, our working memory, has a limited capacity (which depends on various factors: information types, information characteristics and our abilities). In other words, it can only handle a limited amount of information at the time. To help our working memory do its job, we need to break information down into smaller information fragments, also described as units of meaning or chunks.
- Organise the data in a way that reveals meaning. We have to intentionally impose ‘order and structure’ to our data set based on our needs (Glushko, 2013). If a data set is already organised in a certain way, we can change that organisation by arranging the units of meaning with a specific framework. Each way in which we organise units of meaning will reveal different meanings and let us identify hidden/less obvious connections, more/less apparent patterns, or those key aspects of the data that we want to know. A same data set can be ‘organised in a number of different ways and when the results are analysed new patterns emerged’ (Wurman, 1989). We need to find the way that best suits our purposes and helps us save cognitive energy.
- Create categories. Categories are one form of adding order and structure to data, and making it more manageable. Furthermore, by labelling different units of meaning of a data set into specific buckets with similar characteristics, we avoid having to remember everything at the same time. Categories help filter out those units of meaning that are irrelevant for our purposes, while making easily to distinguish the ones relevant to us. ‘Our ability to use and create categories is a form of cognitive economy’ (Levitin, 2014).
- Find connections to what we already know. We find connections when we link chunks or categories to frames already stored in the brain (long-term memory). ‘It is not the things themselves but the meanings or patterns we associate with them that determine our understanding’. We ‘can only understand something relative to something [we] already understand’ (Wurman, 1989).
- Identify patterns and relationships between the units of meaning in the data. We ‘need to develop a set of patterns that [we] can take with [us] and make into [our] own mental map. These patterns are like templates. [We] can recognise sets of information by matching the patterns they form against similar patterns, even if the information in the patterns is vastly different’ (Wurman, 1989).
What should I do if I have to make sense of”¦?
A topic that is unfamiliar. Regardless of the size of the data set, when we encounter data from an unfamiliar subject matter, we most probably do not have useful frames stored in our long-term memory (or if we do have any, the connection to them is not obvious to see). As a result, we experience sensemaking as hard and overwhelming. From a cognitive point of view, these feelings reflect the reluctance of the brain to use large amounts of cognitive energy in order to build frames from scratch that we could then use to extract meaning from data. In some cases, as our familiarity with a topic increases, we will be able to find and reuse frames we have stored from before.
To gain a better understanding of an unfamiliar topic, we can:
- Gather further data to shed light on the topic as it is.
- Break down the topic of the data into sub-topics that we are more familiar with.
- Talk to someone who could explain us what we don’t know.
In all cases, we will use the incoming information and learnings to build the necessary frame(s) to then start making sense.
A data set that is disorganised. Regardless of the size of the data set, when we encounter data that does not have an obvious order or structure, we will struggle to find a flow, narrative or coherent unit. As a result, we will experience similar feelings as in the previous scenario. From a cognitive point of view, the brain will need to use larger amounts of cognitive energy to interconnect components in the data, find connections, and identify patterns.
To provide structure to a data set, we can:
- Use an organising framework (e.g. LATCH, Six ways of seeing) to arrange data with a specific intention.
- Put units of meaning up on a wall and then find a logical way to organise them.
- Use specialised software to provide some structure.
How can information designers help?
Information design skills support the sensemaking process, and are essential across different disciplines and context to tackle information-intensive situations. Some of these skills are rooted in information management and information sciences, while others are more related to cognitive sciences and psychology. These skills equip information designers to help with tasks involving seeking, planning, analysing, chunking, organising, structuring, categorising, connecting, extracting meaning.
‘In an age of information overload, not to mention decision overload, we need systems outside our heads to help us’ (Levitin, 2014). By working with a wide range of techniques (e.g. visual thinking, mapping and diagramming) to externalise thinking and decision-making processes, and impose order and structure, information designers can provide those needed systems.
*NB: In this post, data involves information, content, facts, processes, numbers, concepts, etc.
—
– Dorst, K. & Lawson, B. (2009) Design expertise. Oxford: Architectural Press.
– Glushko, R. (2013) The Discipline of Organizing. The MIT Press.
– Levitin, D.J. (2014) The Organized Mind: Thinking Straight in the Age of Information Overload. Dutton.
– Malamed, C. (2009) Chunking Information for Instructional Design. [Online]
– Moles, A., 1966. Information theory and aesthetic perception. Translated from French by J. E. Cohen. Urbana, London: University of Illinois Press.
– Wurman, R. S. (1989). Hats. Design Quarterly, 1-32.
Leave a Reply